jRelational Frameworkenterprise java beans |
The jRelational Framework is an implementation of the Sun Data Access Object pattern.
The jRelationalFramework has been used very successfully with more than one EJB project we have done here at is.com. This framework was born out of the performance limitations of Container Managed Persistence (CMP) Entity beans. Because the EJB specification in 1999 was still relatively new there were few best-practices that had been defined. This page was written to help you learn from our mistakes, so that you can create a scalable system the first time around. We think that the jRelationaFramework is well suited for use in a scalable EJB architecture:
Our first attempt at an Enterprise Bean architecture had 3 bean layers. The first layer was made up of stateless session beans that were the interface to the client. The second layer also consisted of session beans, but they mapped the CMP entity beans to value objects. The lowest layer was the Entity bean layer with each bean class mapped to one table. The picture below illustrates this architecture.
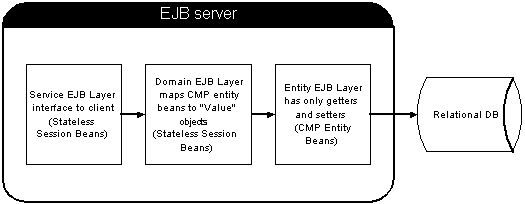
Not until we had gotten a ways into development did we realize why this would not scale:
According to the latest Sun Enterprise Blueprints, which are best practice principles for J2EE and EJB, an entity bean is better suited to represent a coarse-grained business object that provides more complex behavior than only get and set methods. In other words, we should shy away from entity beans that map to one table only and have no business logic. This concept can apply to either entity beans or session beans. Our final architectures have chosen to use session beans.
Also according to Sun's Blueprints, only the business objects that need to be accessed directly by the client need to be enterprise beans: use helper objects. Our use of the middle "domain" EJB layer and use of entity beans as simple data holders violated this principle.
Our solution was to create a data access helper superclass (which eventually became the AbstractDomain class of the JRF framework) that replaces both the "domain" layer and the entity layer. The "service" layer then consists primarily of pass-through methods to the domain helper classes. This allows the "service" beans to do what they do best: managing transactions and security.

One of the biggest benefits to switching to this architecture was that we reduced the number of source code files by at least 40% while gaining much faster response times without losing any functionality.
See the Sun Value List Handler Pattern for a good explanation of how to use Data Access Objects (jRF) to page cached result sets on the server.
top
main page
noticed
a document error?
copyright © 2000 is.com![]()